缩放和字体渲染问题
概述
此页是总览, 主要是收集的研究资料, 产生的实验和扩展内容将在其他页面实现, 主要针对linux 字体渲染内容给予扩展, 字体渲染在任何平台的评价都是猛兽,需要更多的专业知识来驾驭.
问题
- freetype2使用mac类似的字体渲染算法后, kde wayland环境4k缩放150%之后失效了
- 缩放存在着次表面舍入问题以及其他的像素逻辑坐标和物理坐标对齐问题 测试工具如下: aligned-scale-test fractional-scaling
freeype2只是进行最后的字形光栅化, 由cpu来完成, 目前也有SDF这样的完全由GPU光栅化器 完成的过程, 字形看起来更清晰 锐利(sharp).
目前可以明确两点
- 在渲染堆栈中窗口内容的字体渲染主要通过ui库来完成和合成器的关系不大
- 字形光栅化存在基于cpu和GPU的两条路径
后续看看GTK 和 Qt两套ui库分别如何完成的字体渲染过程以及遵循的策略是什么(最大限度遵循字体设计师给出的 字形hint(apple)还是遵循以易于阅读作为字形渲染的策略(window))
文本如何呈现
我们在CPU上修改这些字形的形状, 对他们进行变换, 而字体的大小进行resize, 他在CPU上将纹理上穿到GPU并进行blit处理 问题是如果你想更改字体的大小,则必须重做. 如果有动画文本,则必须重新调整大小.
我们需要弄清楚如何在高分辨率下做的更好. 也就是更高dpi的设备.
过去30多年以来, 每个人都在cpu上做, 这就是我们所说的基于覆盖的antialising 所以基本上你画出像素, 在形状上看有多少, 像素被覆盖的百分比是多少, 然后根据覆盖率分配数字, 灰色阴影
字体格式
GPU文本渲染技术
GPU text rendering techniques. GPU Text Rendering Techniques Part II GLyphy: high-quality glyph rendering using OpenGL ES2 shaders - Behdad Esfahbod multi-channel signed distance field generator msdf font atlas generator
缺点:
- 为了捆绑来自不同语言的字形,应用程序的大小将显着增加。
- 使用不同的样式(粗体/斜体等)将进一步突出问题。
- 即使以某种尺寸渲染字形并以不同的尺寸显示也会影响显示质量。
字体测试
Your International Type Fonts Multilingual support (East Asian) UTF-8 test page

Figure 1: 1080p font display
Xwayland
支持客户端原生缩放,无需缩放Xwayland分辨率,避免Xwayland模糊
WIP: xwayland: Multi DPI support via max factor rescaling Draft: xwayland: Multi DPI support via global factor rescaling Draft: xwayland: Multi DPI support via global factor rescaling [updated using properties]
mutter
目前,GTK 仅支持字体的分数缩放。另一方面,小部件(如按钮或标签)只能使用整数 (DPI) 缩放。因此,大多数本机 GNOME 应用程序的分数缩放需要首先以更高分辨率渲染,然后缩小到所请求的分辨率。 GTK 在 Wayland 和 Xorg 会话中都使用了这 种技术。 对于某些运行 GTK 3 应用程序的设置,这可能会增加 CPU 和 GPU 使用率以及功耗,从而导致响应速度较低的体验 特别是在 Xorg 中。
- Has two modes!
- Currently due to X11 everything is done in device pixels, sending logical pixels down the wwire with compositor maths
- Has a mode similar to kwin and sway
Fractional Scaling Known issues and TODO gnome fractional scaling hackfest Rendering Text with Glyphy
gtk
- DPI 仅在 X11 上真正用于辅助功能并且是全局的
- GTK4 仅具有整数缩放功能,至少在 GTK5 之前不会改变
kwin
kwin 以及实施wayland的新协议 fractional scale protocol它允许 Qt 工具包打开其在 Wayland 上预先存在的分 数缩放支持,而这在 X11 上一直都有。不再渲染为整数大小然后缩小!这应该会导致缩放到 100%、200% 或 300% 以外的任 何比例的 Qt 应用程序具有更好的性能、更少的视觉模糊和更低的功耗。
kwin implement wp-fractional-scale
- Uses logical pixels throughout rendering, scaling in the rendering. Has a snap to grid
- Due to feedback looking at creating a manual opt out (mostly for X11) and have a different scale for kwin vs what gets sent as logical pixels down the wire.
QT
- Combination of DPI information and scale which can be completely floating
- One only adjusts text, the other affects all drawing
- Has a concept of “logical space” and “device pixels”
qt hight dpi steam hidpi scaling text and font handling introducing the distance field generator
Text Rendering: Kerning and Glyph Atlases
Adventures in Text Rendering: Kerning and Glyph Atlases Improving the Font Pipeline good quality subpixel text rendering in opengl Easy Scalable Text Rendering on the GPU
这是对文本渲染的深入探讨——整形、光栅化以及在不牺牲质量的情况下优化性能的挑战。
从游戏引擎到网络浏览器再到终端,一些应用程序放弃系统 UI 框架,直接在 GPU 上进行大部分渲染,以便利用特定于上下文的优化。 当涉及文本时,这些应用程序 承担许多通常被抽象到更高级别系统框架后面的职责,并且很难获得底层文档。
我想首先分享文本渲染管道的概述,从字体系列到屏幕上的像素,之后我将介绍针对文本密集型应用程序的特定性能优化,例如我工作的 GPU 加速终端 Warp在。
Text Rendering
在进入渲染过程之前,我们首先需要了解我们依赖的主要数据源——字体。
字体是显示具有特定设计、粗细(粗体)和样式(如斜体)的字符串所需的信息的集合。 具有特定设计的一组字体一起称为字体或字体系列(例如 Times New Roman 或 Comic Sans)。 字体可以是成比例的 - 每个字符仅占用所需的空间 - 或等宽字体 - 每个字符占用相同数量的水平空间,与字符本身的宽度无关(有时称为“固定 宽度”) 。 您在计算机或网络浏览器中遇到的大多数字体都是成比例的,但在编程环境中,例如代码编辑器和终端,等宽字体几乎是普遍首选。
字体包含两个主要类别的数据:
- 与字形相关的信息 - 代表一个或多个字符的图形符号
- 描述如何相对于彼此定位字形对的说明
当两个或多个字符组合成一个字形时,称为连字。 传统的连字示例包括 æ 和 ffi(三字符连字)。终端用户可能更熟悉将 > 组合成 ⇒ 或 ~ 组合成 ≃ 的
字体,这些示例可以在许多面向编程的字体中找到。
大多数字体将字形表示为矢量图形(想想 SVG 图像)——指定字形轮廓的线条、形状和曲线的数学描述。 有些字体是位图字体(想想 JPG 图像)——它们将字形表示为像素网格 (有些打开,有些关闭)。 矢量字体更为常见,因为它们可以缩放到任何大小,无论大小,而不会损失任何精度或图形保真度。
现在我们知道数据来自哪里,我们如何使用它将一串字符转换为一些渲染良好的文本? 该过程可以分为两个主要部分:整形(shaping)和光栅化(rasterization)。
整形 :获取文本字符串(在我们的例子中为 Unicode)字符列表并将其转换为一组要在特定位置呈现的字形的过程。
光栅化 :采用矢量图形格式描述的字形(或其他图像)并将其转换为“光栅图像”(或位图)(一系列像素)的过程。 图形芯片本身并不理解矢量图形,因此在处理此类数 据时,光栅化为位图是必要的步骤。
As alluded to above, there are more steps than solely these two - itemization, line breaking, and justification are also involved in the overall layout process.
这两者都相当复杂,并且几乎所有应用程序都将繁重的工作委托给了库,这些库通常是操作系统本身的。在 MacOS 上,布局和光栅化均由 Apple 的 Core Text 库执行。 在 Windows 上,相当于 Microsoft 的 DirectWrite 库。在 Linux 上,标准化程度较低,但 Pango 是布局的常见选择,而 FreeType 是光栅化的常见选择。 虽然我们可以依靠库来为我们完成工作,但我们仍然需要更多地了解这两个过程。
Shaping
我们在这里关心的塑造的第一部分是从字符列表到字形列表的转换。 在某些语言(例如英语)中,转换非常简单,使用从字符到字形的 1:1 映射,连字是可选的 美学选择。 通过查询字体的连字数据表并确定是否要进行任何替换来确定连字的使用。
然而,在许多其他语言中,需要替换才能正确显示文本。 HarfBuzz(一种流行的整形引擎)的文档中描述了一个示例:
1For example, in Tamil, when the letter "TTA" (ட) letter is followed by the vowel sign "U" (ு), the pair
2must be replaced by the single glyph "டு". The sequence of Unicode characters "ட,ு" needs to be substituted
3with a single "டு" glyph from the font.
4
5But "டு" does not have a Unicode codepoint. To find this glyph, you need to consult the table inside the font
6(the GSUB table) that contains substitution information. In other words, text shaping chooses the correct glyph
7for a sequence of characters provided.
阿拉伯语是另一个例子,其中用于特定字符的字形取决于该字符在单词或文本字符串中的位置。
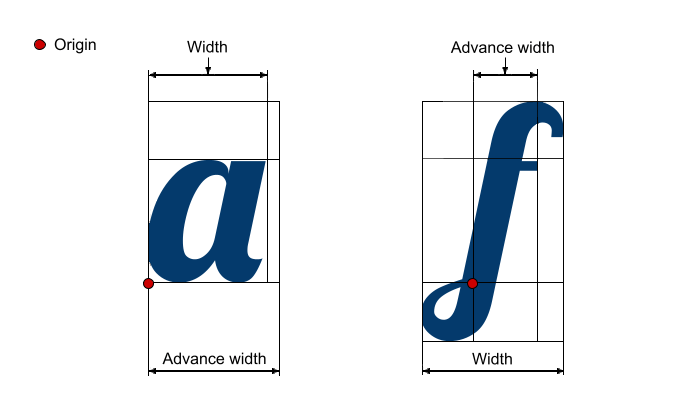
一旦我们获得了表示给定文本字符串的字形列表,我们仍然需要另外两条信息来呈现该字符串:字形的位置以及它们的实际外观。 我们将从定位开始,因为 这更容易一些。
整形引擎的运行与页面上的位置和渲染区域的边界无关 - 它的作用就好像有一个无限宽的空间来布局文本。最终,它只关心字形相对于其前身的位置 - 称为字形前进的属 性(沿 x 轴和 y 轴前进多少以到达下一个字形的位置)。前进与字形本身的宽度无关 - 例如,空格字符没有视觉宽度,但具有非零前进(将前一个和下一个字符彼此分开)。
{kind=link}
对于 Warp 用于终端输入和输出的等宽字体,字形advance是一个常数 - 所有字形对之间使用固定的间距量。 对于比例字体,advance是可变的,因为不同的字形具有 不同的宽度。 小写字母 L 比大写字母 W 窄,并且对每个字母使用相同的advance会导致小写字母 L 周围出现尴尬的大间隙,或者让 W 感觉局促。
不幸的是,仅仅考虑字形的宽度不足以生成具有比例字体的美观文本。某些字形对(例如大写字母 A 和 V)由于形状原因,即使考虑字形宽度,也感觉相距太远。在这些情 况下,字体作者会指定一个额外的调整因子,该因子应该应用于这对字形,以保持所有内容在视觉上令人愉悦。进行这些调整的过程称为字距调整

Figure 3: what negative (blue) and positive (yellow) kerning adjustments look like in the Glyphs font creation app
通常阅读速度较慢,尤其是当字母太靠近而难以视觉解析时。 字体创建者将手动覆盖字符对之间的advance,以保持可读性并提高美观性。 请注意上图中 V 和 A 之间 的重叠程度 - 如果没有字偶距调整,文本看起来更像“V AND”。
现在我们知道字形应该出现在哪里,那么我们到底在这些位置绘制什么?字形实际上应该是什么样子?
Rasterizing
如上所述,对于矢量字体,我们需要光栅化我们的字形(从矢量转换为位图)以将它们放在屏幕上。 在较高层次上,这是通过将字形的矢量描述“放置”在像素网格的 顶部,并检查哪些像素包含在字形的“着墨”区域内来实现的。 在这里,一张图片很容易抵得上1000个字:
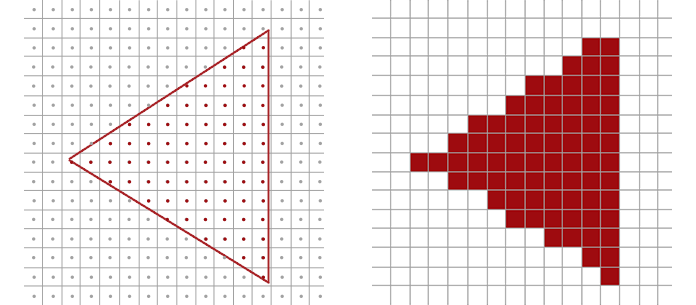
Figure 4: 一对演示光栅化过程的图像 - 填充中心位于矢量轮廓内的像素;中心位于轮廓之外的像素将被忽略
最简单的光栅化策略如下:对于所考虑的每个像素,检查像素的中心是否位于矢量轮廓内。 如果它在轮廓内部,则该像素被打开。 如果它位于轮廓之外——即使只有 最微小的边缘——该像素将被完全忽略。 (这种二进制开/关称为黑白或双层光栅化。)虽然这是一个简单的计算,但结果看起来不太好 - 一个简单的三角形开始看 起来很混乱,当它不与底层像素网格很好地对齐。 右侧的三角形是混叠(aliased),这是信号处理中的一个术语,用于描述由于信号频率(我们的矢量轮廓)和采 样频率(我们的像素网格)之间未对准而导致的不准确性。
为了消除锯齿状边缘,我们需要利用一种称为抗锯齿的过程(谁能猜到!)。如果我们的采样(像素中心)不能产生源材料的准确近似值,我们可以增加采样频率以获得 更好的估计。一种抗锯齿方法是超级采样 - 检查每个像素内的少数点,并根据矢量轮廓内的样本百分比对像素进行着色。
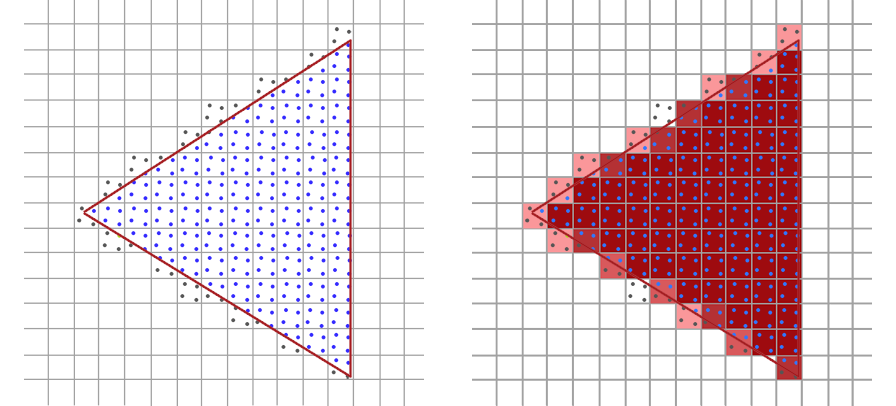
Figure 5: 我们可以对每个像素内的 4 个点进行采样,然后对结果进行平均,而不是仅对每个像素的中心进行采样。
在我们的三角形示例中,增加采样频率可以提高光栅化图像的准确性 - 例如,请注意三角形的顶角如何不再丢失。通过提高采样率可以更好地近似原始矢量数据,但成本 会增加(与样本数量成线性关系)。除了三角形之外,完全相同的过程也适用于复杂的矢量形状.
现代文本渲染更进一步,利用了 LCD 显示器具有三个独立的、独立控制的子像素这一事实,这些子像素由每个像素的红色、绿色和蓝色分量组成。此过程(子像素抗锯齿) 在每个子像素级别执行采样,并调整结果以确保彩色子像素不会影响字形的感知颜色。
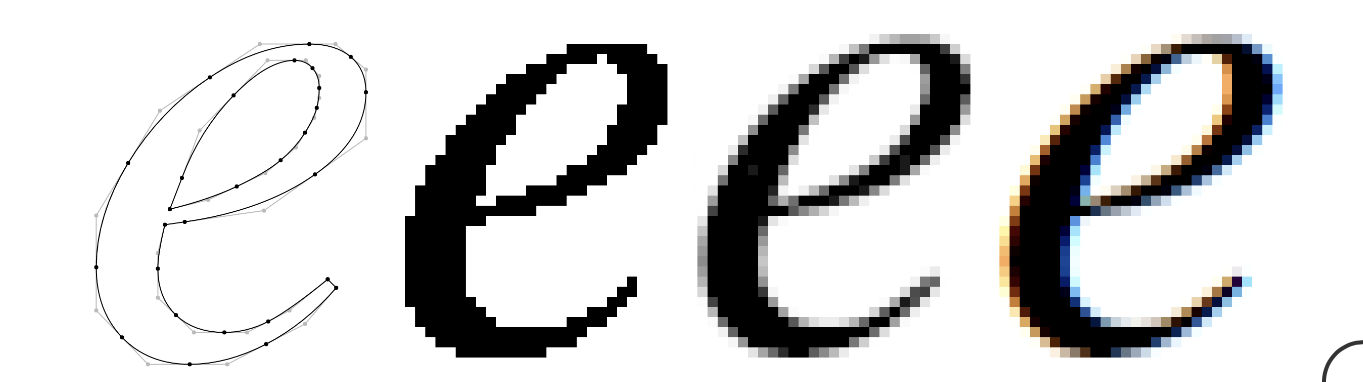
Figure 6: “e”字形的矢量表示,以及双层、灰度抗锯齿和子像素抗锯齿光栅化的输出
虽然人们普遍认为它在较低分辨率的显示器上会产生更好的结果,但并非所有平台都支持子像素抗锯齿光栅化。事实上,MacOS 随着 Mojave 的发布而放弃了对其的支 持,因为其高 DPI“视网膜”显示屏的边际收益并没有超过实现的复杂性
TLDR: - 文本渲染是决定字形应该去哪里、将任何矢量字形转换为位图表示形式,然后在屏幕上显示这些位图的问题。听起来很容易!那么,呃,我为什么要费心写一篇 关于它的博客文章呢?当我们超越简单的解决方案 - 性能时,通常会出现这种情况:)
Speeding up Text Rendering with a Glyph Atlas
将大量矢量描述的字形转换为其位图等效项并不是最快的操作。 那么,当我们多次执行一个操作并且给定输入时输出始终相同时,我们该怎么办?添加缓存! 我们可以在两个不同级别进行缓存:行级缓存(缓存整个形状和光栅化文本行)或字形级缓存(缓存每个光栅化字形)。 鉴于我们的大多数字形都是等宽终端网格 的一部分,我们使用固定的advance并且可以忽略字距调整,并且当数据写入 stdout/stderr(字形级别)时,行的内容可能会频繁更改缓存将在性能和内存消耗之间 提供更好的权衡 - 行缓存将包含相同光栅化字形的许多副本。
鉴于我们使用 GPU 进行渲染 6,我们特别想要构建的是字形图集。
字形图集(glyph atlas)是一个 GPU 纹理(图像),其中包含我们需要向用户展示的字形的所有光栅化位图。 我们不是每次重绘应用程序时都执行矢量 → 位图转换,而是将 结果存储在纹理中,然后要求 GPU 将位图从图集纹理“复制”到输出缓冲区中的正确位置(我们所在的纹理)正在渲染窗口内容)。 我们将字体 ID、字形 ID 和字体大小组合起 来形成缓存键,确保任何“缩放”均由光栅化器执行,这将产生比 GPU 上的最近邻缩放或双线性缩放更清晰的结果(放大时) 。 当图集纹理充满字形时,我们会创建另一个纹理; 在渲染时,我们告诉 GPU 哪个纹理保存有问题的字形以及该字形在纹理中的位置。
对于终端网格来说,这非常有用! 我们可以轻松地将网格可见部分内的(行、列)对映射到屏幕位置,并让 GPU 将图集中的字形复制到输出缓冲区中的该位置。 当我们为 GPU 构建渲染指令列表时,如果我们需要显示尚未在图集中的字形(缓存未命中),我们将对其进行光栅化并将其插入图集纹理中。 这种“惰性”缓存填充策略有助于我们最大限度地减 少 GPU 内存消耗。
但是 UI 的其余部分呢? 使用比例字体(例如 Roboto,我们目前使用它来渲染 UI 文本),两个字形之间的提前量可能是 2.46px 之类的值。 我们可以 要求 GPU 将 字形定位在分数水平位置吗? 当然! GPU 可以轻松做到这一点 - 当目标像素未与单个源像素对齐时,GPU 会将所有 2 或 4 个重叠像素的值(按比例)混合在一起,以确 定目标像素的值。 好的!
没那么快。 当源像素和目标像素未对齐时,让 GPU 进行混合会导致字体模糊。 不好。
这里最简单的解决方案,也是长期使用的 Warp 解决方案,是将字形的水平位置舍入到最近的像素边界,以避免 GPU 混合。 虽然我们保持文本看起来清晰(耶!),但我们没有 尊重整形引擎提供的精确定位信息,这意味着我们最终会得到字距不佳的文本(以及不满意的用户 - 嘘!)。
那么 - 我们如何保留字形图集的性能优势、避免文本模糊并确保正确的字距调整?
Replacing Approximations with Better Approximations
如上所述,光栅化器的输出取决于基于矢量的字形如何与底层像素网格重叠,因此将字形图集的“缓存键”限制为 (font_id, glyph_id, font_size) 是不正确的 - 我们 需要添加一个组件,对字形相对于像素网格的位置进行编码。
让我们停止将字形位置捕捉到最近的像素边界并创建缓存键 (font_id, glyph_id, font_size, fract(glyph_position.x))。 不幸的是,这实际上使缓存变得无 用 - [0,1) 范围内可能的浮点值集非常大,并且由于浮点不精确,我们甚至不能确信我们总是会得到相等的值分数水平位置的值。 鉴于字形图集的好处之一是减少内存使用, 我们可能不希望拥有无限大小的缓存:)。
如果我们不想使用一份副本,也不想使用“无限”副本……如果我们使用 N 份副本怎么样?